An Introduction to Graph Query Languages
In the previous section, we reviewed the graph database ecosystem and got an understanding of the different types of options available, frameworks, RDF Triplestores, and labeled property graph databases. In this section, we are going to provide an overview of the more common query languages used by graph databases and examine what each query language looks like using our “Friend of a Friend” use case.
In the RDBMS world, SQL is the standard query language that is supported by most to all databases on the market. In the graph database world, the immaturity of the technology and ecosystem has led to a lack of a single standard query language support. While there are a few emerging standards out there, many database vendors either support multiple different query languages, such as AWS Neptune or Neo4j or have created their custom query languages to fill gaps in these standards, such as DGraph and OrientDB.
There is not a graph query language for property model graphs that is supported by the majority of the databases on the market. Due to the fractured nature of the space, there have been several attempts of the recent years to create a unified graph query language managed as part of an international standards bureau, in much the same way that SQL is for relational databases. At the time of writing this book, there is a new proposal underway to formulate a new standard property graph query language called GQL. GQL is based on three current query languages, PGQL from Oracle, G-Core from the Linked Data Benchmark Council, and Cypher from Neo4j .
While there is active work being done to come to agreement on a standard and formalize this for submission to a standards board, at this time, there is not a concrete implementation of what this language might look like or how it may work, but it will be interesting to see how this proposal develops over time.
This lack of standardization means that your chosen database option dictates the language or languages that you can use to query that database. While this is not necessarily the ideal scenario, it is the reality in the industry today. So, if the database drives my choice, then why even go through the options? While it is true that you will only have a limited set of options to choose from once you have decided on a database it is still valuable that we understand the different options on the market today and their strength and weaknesses since these aspects may be a determining factor when choosing a final database technology.
SPARQL
SPARQL (SPARQL Protocol and RDF Query Language) is the query language and data access protocol for the semantic web. SPARQL is a W3C (World Wide Web Consortium) standard and the query language for RDF (Resource Description Framework) data and is supported by most RDF TripleStore databases. SPARQL allows us to query and manipulate data using triples, as well as perform complex operations such as joins, projections, and pattern matching. Using our “friends of friends” graph from earlier, let’s take a look at some SPARQL queries:
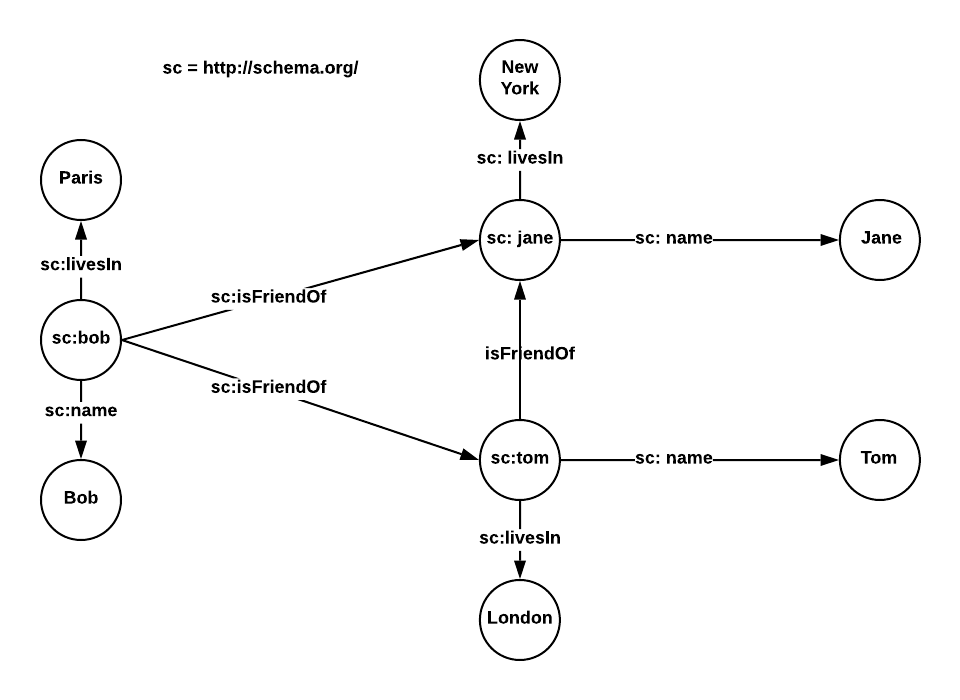
What would a SPARQL query look like to answer, Find the name of all of Bob’s friends?
PREFIX sc: <http://schema.org/>
SELECT ?friendName WHERE
{
http://bob sc:isFriendOf ?f .
?f sc:name ?friendName.
}
Results Returned: [Jane, Tom]
Let’s extend that query a bit to Find the name of all Bob’s friends that live in New York?
PREFIX sc: <http://schema.org/>
SELECT ?friendName WHERE
{
http://bob sc:isFriendOf ?f .
?f sc:livesIn livesIn:”New York” .
?f sc:name ?friendName .
}
Results Returned: [Jane]
The important takeaway is to see how SPARQL expresses the subject-object-predicate nature of the triple, not the exact SPARQL syntax used. While a few labeled property graph databases support SPARQL, in addition to another language, such as AWS Neptune, this support in labeled property graphs is not common due to fundamental differences in the RDF and labeled property model data structures.
Cypher/openCypher
Cypher is a graph query language that was originally developed by Neo4j for use in their database. In October 2015, they released Cypher as an open language specification via the openCypher project. openCypher is currently implemented, either in part or wholly, by 11 different vendors (as of Nov. 2018) including Neo4j , as well as SAP HANA , AgenesGraph and Memgraph .
NOTE: In the context of this book, when I refer to Cypher I am specifying to content that is inclusive of both Cypher, which is Neo4j’s implementation, or other openCypher implementations.
Cypher is a declarative graph-based query language that aims to provide an easily readable mechanism to traverse graphs using an expressive, efficient and intuitive syntax. Cypher traversals are made up of a variety of clauses and projections that feels very intuitive to users familiar with SQL. While the language is not identical, many of the usual patterns and practices in SQL are also available to Cypher users.
Let’s take a look at some queries using Cypher in our “friends of friends” graph:
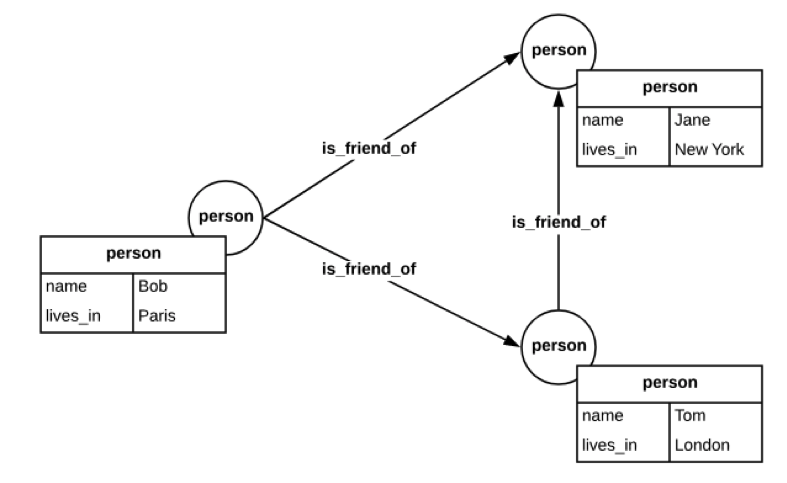
As we did with SPARQL, let’s examine the query, Find the name of all of Bob’s friends?
MATCH n (me:Person)-[:is_friend_of]->
(myFriend:Person)
WHERE me.name=’Bob’
RETURN myFriend.name
Results Returned: [Jane, Tom]
And extending that query to Find the name of all Bob’s friends who live in New York?
MATCH n (me:Person)-[:is_friend_of]->
(myFriend:Person)
WHERE me.name=’Bob’
AND myFriend.lives_in=’New York’
RETURN myFriend.name
Results Returned: [Jane]
In the queries above, we can see the declarative nature of the Cypher syntax and its similarity to SQL. When you write a Cypher traversal, you are declaring the pattern of the data you would like returned. The underlying engine then takes this declaration and determines the optimal solution in which to traverse the graph similarly to how a SQL engine works in your RDBMS system. This declarative nature of Cypher provides an easy to use query language but can encounter some issues working on complex traversals where the engine may struggle to optimize the traversal.
2.2.3 Apache TinkerPop Gremlin Gremlin is the query language created by the Apache TinkerPop project. At the time of writing this in November 2018, there are currently 22 Tinkerpop-enabled databases on the market, including some of the big players that implement it as their primary query language such as Datastax Enterprise Graph , Azure CosmosDB , AWS Neptune , and JanusGraph . Several other vendors implement Gremlin as an additional query language to their native one such as StarDog , OrientDB , and Neo4j .
Gremlin traversals are composed of steps, each of which performs either a map, flatMap, branch, filter, or sideEffect operation on the data. Gremlin is a lazily evaluated language, so each step builds upon the output of the previous step. It is helpful to think of Gremlin as a stream processor with each step performing a single operation on the stream of data. Each step takes in data output by the previous step, performs some action on that data, and passes that data on to the next step. Using this basic paradigm, you can compose extremely complex operations with Gremlin. Let’s take a look at some queries written in Gremlin.
As we did with both SPARQL and Cypher, let’s see the Gremlin query, Find the name of all of Bob’s friends?
g.V()
.has(‘person’, ‘name’, ‘Bob’)
.out(‘is_friend_of’)
.values(‘name’)
Results Returned: [Jane, Tom]
Now let’s look at the query, Find the name of all Bob’s friends that live in New York?
g.V()
.has(‘person’, ‘name’, ‘Bob’)
.out(‘is_friend_of’)
.has(‘person’, ‘lives_in’, ‘New York’)
.values(‘name’)
Results Returned: [Jane]
As we can see from the examples Gremlin queries, Gremlin does not look similar to the SPARQL or Cypher queries but appear much more like a programming language. Gremlin is a functional language and allows you to step through your graph to express complex traversals using either an imperative or declarative syntax. Using the imperative syntax of Gremlin, as shown above, is the most common. Throughout this book, we will use the imperative Gremlin syntax, but it is good to know that the declarative syntax exists. Below is the query, “Find the name of all Bob’s friends that live in New York?,” written in Gremlin’s declarative syntax.
g.V().match(
__.as(‘a’).has(‘name’, ‘Bob’).as(‘b’),
__.as(‘b’).out(‘is_friend_of’).as(‘c’),
__.as(‘c’).has(‘person’, ‘lives_in’, ‘New York’).as(‘d’)
).select(‘d’).by(‘name’)
When working with declarative Gremlin queries, you specify a pattern or patterns that you want to find within your graph, and the underlying compile and runtime optimizers determine how to execute the query. With either query methodology, you can efficiently traverse through your graph to find and manipulate data within your graph.
GraphQL
GraphQL was initially developed by Facebook and was designed to serve as an alternative data query pattern for web services. GraphQL is a data query and manipulation language that provides flexible and extensible queries for APIs. GraphQL queries are specified using JSON-like strings of data that define the structure and content of the data required. These queries allow the client to specify only the fields and structures that they need to be returned by the query, thereby minimizing the amount of potential data transfer from the client.
As in the previous sections, we are going to use our “friends of friends” graph to demonstrate a GraphQL query.
Let’s see what the GraphQL query, “Find the name of all of Bob’s friends?.”
{
Person(name: ‘Bob’) {
is_friend_of {
name
}
}
}
Results Returned: [Jane, Tom]
Now let’s look at the query, “Find the name of all Bob’s friends that live in New York?”
{
Person(name: ‘Bob’) {
is_friend_of (lives_in: ‘New York’ {
name
}
}
}
Results Returned: [Jane]
GraphQL is often referred to as a graph query language and is even implemented as such by several graph databases such as DGraph . While arguably not a graph query language in the same way as Gremlin or Cypher, there are many graph databases, such as Neo4j and ArangoDB that provide tight integrations between their databases and GraphQL to deliver a simpler mechanism for creating web service endpoints on top of their databases.
SQL Derivatives
Some graph databases have created their own custom SQL-inspired graph query languages, such as ArangoDB AQL, or have extended SQL to handle graph constructs, such as OrientDB . These efforts have intended to extend and enhance a popular query language standard to allow for easier developer adoption and to minimize the learning curve. Each of these offerings is optimized to leverage the unique features of that specific database. We are not going to review an example here due to the vast numbers that exist and the fact that each option has its unique syntax.