Graph Databases
RDF and Property Model
Let’s say that instead of wanting to find the most influential person in our Twitter data we just wanted to recommend people for you to follow. To determine this answer, we would want to traverse our graph to find all the people that you follow then find everyone that they follow that you don’t. This type of problem is similar to what we did in the social network use case of GluttonApp. Unlike the global requirements of finding centrality, tree traversal and neighborhood calculations require that process a local subgraph of only the vertices and edges that are near our start vertex to get our answer. Processing these more straightforward calculations on a localized subgraph makes a graph database an optimal choice. Graph databases are technologies that are optimized for running graph computationally simpler computations, such as neighborhood or tree traversals, against subgraphs. Unlike graph frameworks, graph databases do not rely on external data sources or processing frameworks to run graph computations or the storage and retrieval of the data.

Many of the graph databases on the market can run both transactional (OLTP) and analytical (OLAP) workloads against their data; however, OLAP workloads commonly use additional frameworks, such as Apache Spark, to handle the large-scale processing operation similar to the way a graph framework works.
As a general rule, each database in the graph database ecosystem is either an RDF/Triple Store or a Labeled Property Model database. In the next section, we will examine the differences between these two types.
RDF Triple Store
Let’s say we needed to store the meaning of tweets, also known as the semantics so that we can infer how two users are related (e.g., If two users are tweeting about the same topic, then it is likely they are connected). Problems such as this leverage the dominant feature of an RDF Triplestore which is the ability to infer meanings and relationships between data. RDF Triplestores accomplish this by storing data in a way that facilitates the ability to infer and extract meaning from data that is not known at the time of creation. An RDF Triplestore stores these facts based on ontologies (a formal naming and categorization of information) using the Resource Description Framework (RDF). RDF is a W3C standard for defining data interchange on the internet. The semantic web is an extension of the W3C standards that provide the web with better standardization for data formats and interchange protocols.
RDF Triplestores store data based on a Subject - Predicate - Object paradigm known as a triple. In RDF databases, the subject and object of a triple are created as vertices in the graph, and the predicate is an edge connecting the two. This method of modeling allows for efficient storage and retrieval of highly connected data while allowing for extensible flexibility regarding the data model and schema. Let’s take a look at what it would look like to store the fact that Bob lives in Paris in a triple and how that triple is represented in an RDF TripleStore.
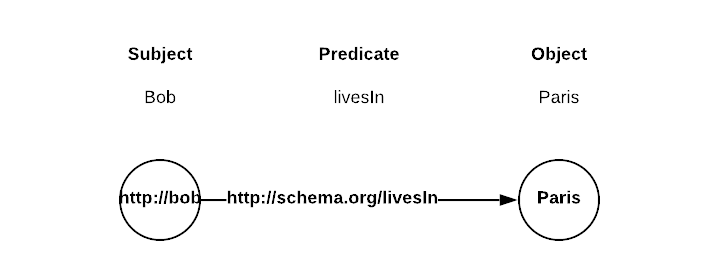
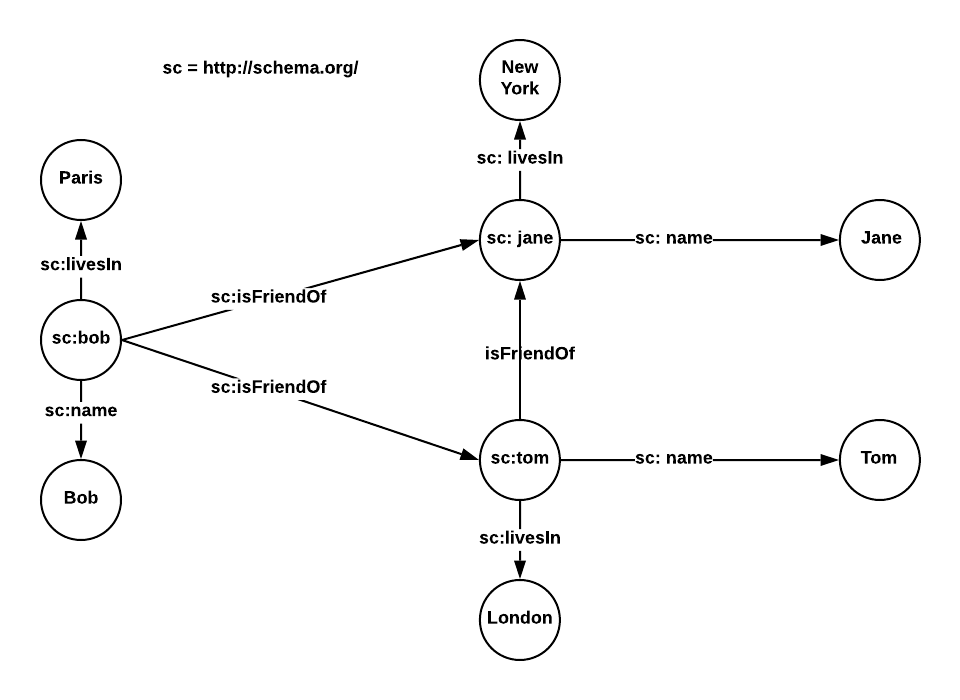
One of the things you will notice is that RDF defines each Subject and Predicate in the triple as identifiable by a Universal Resources Identifier (URI). This requirement is by design since the primary usage of RDF is to allow information to be easily read and understood by computers, not by humans. This URI requirement means that looking at visual representations of this data is complicated, so the leading portion of the schema is often shortened for readability. In the figure below, the sc:bob vertex should read as http://schema.org/bob.
Other than how the data is stored the other defining characteristics of RDF triplestores is a dominant feature of the inference engine, which uses the defined ontologies and data to deduce of new relationships about the data. We know that this sounds very confusing, but the best way to understand how these items work together is to look at the example see how an inference engine works. We first start by describing our ontologies:
People own cars People are married to people
We then describe the instance data:
John owns a Mercedes
John is married to Mercedes
With these two pieces of data, the inference engine can deduce the new facts about our data.
John owns a car of type Mercedes
John is married to a person named Mercedes
This ability to deduce new information based on inference is one of the features that uniquely distinguishes RDF triplestores from other databases. The downside of inference engines is that the performance varies based on the complexity of our ontologies.
Typical examples of RDF triplestores include:
- StarDog
- AllegroGraph
- Virtuoso
- Ontotext
Labeled Property Graph
Let’s say we want to find out how you are related to someone else based on who you follow. To answer this question, we are looking for a way to rapidly traverse known relationships. The ability to efficiently traverse known relationships is one of the strengths of Labeled property graph databases due to the strong materialization of relationships within the graph. Unlike other graph databases which consist of nodes and edges, labeled property graph databases also have properties and labels associated with each node and edge. This additional features of labels and properties distinguish labeled property graphs from RDF triplestores. Labeled Property model graphs are optimized to provide efficient and performant traversals of these sorts of known relationships
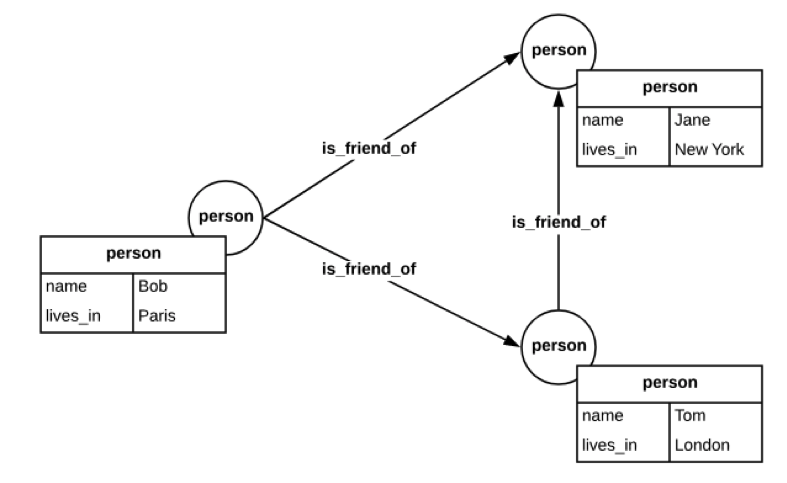
To better understand how a labeled property graph database works let’s begin looking at labeled property graph databases by breaking down the individual components of the name starting with “labeled”.
Labels are a string used to group nodes or edges into unique sets; you can think of labels similar to a table name is used in RDBMS systems. The label provides meaning to the data being stored and is one of the primary criteria used when filtering queries. In the figure above, both person and is_friend_of are the labels in our friends of friend’s graph.
Properties are the set of key-value data attributes associated with a node or edge. Properties are the feature of this type of database that allows us to store the relevant attribute data for a specific node or edge. In a labeled property graph, both nodes and edges can have one or more properties associated with them. The ability to add properties to a node or edge in a graph is one of the significant differences between RDF databases and labeled property databases. Unlike RDF databases, labeled property graph databases allow us to store complex data structures and schemas on nodes and edges instead of exploding that information into the graph itself. In the figure above, both name and lives_in represent properties associated with the nodes labeled person. Unlike RDBMS systems, the schema for properties between nodes is not required to be consistent in a labeled property graph.
The two features described here, labels and properties, are what differentiate labeled property graphs from other types of databases. Combining these features allows treating relationships as strong links between entities that can provide both semantic meaning and metadata. This ability to create strong connections between data is one of the most powerful features that property model graph databases offer. When you combine all the attributes of the labeled property graph database, we have a tool that provides the ability to create a semantically rich data structure that closely resembles your logical data model, while providing the flexibility that traditional RDBMS systems do not offer.
Typical examples of Labeled Property Graph databases include:
- Neo4j
- JanusGraph
- Datastax Enterprise Graph
- Amazon Neptune
- Azure CosmosDB
- MemGraph
- OrientDB
- ArangoDB
- DGraph