Graph Frameworks
Let’s say that we wanted to find the most influential person in our Twitter data based on the number of followers, retweets, and likes on his posts. To answer this question, we would likely look to use one of the different centrality measurements we discussed in Chapter 10. As we know each of these centrality measurements needs to process all of the data in the dataset to calculate this metric. Each of these calculations is very processing intensive (e.g., PageRank is O(n*m) complex) so running this on a dataset as large as our Twitter data would require working with data spanning many machines and the amount of computation time would likely in the range of hours or days.
Questions that require processing most to all of a dataset and/or require running computationally complex algorithms (e.g., PageRank) falls into a set of problems known as analytical graph questions. If your problem is all about answering these questions, then I would suggest you use a graph framework. Graph frameworks are uniquely constructed to handle running computationally expensive algorithms on data sets too large to fit on a single machine. The tradeoff of using a graph framework is that the calculations do not occur in real time, so all the processing is done via an offline batch process.
In our Twitter example, the global nature of data required, and processing time needed to find the most influential person in NYC would far exceed the memory and computational power of servers on the market today, so a graph framework that it is optimized for parallel processing across many servers is a prudent choice.
To use a graph framework, an application first loads the data from the system of record, such as an external database or CSV file, into the graph framework. This loading process is often accomplished using an Extract/Transform/Load (ETL) approach familiar in data warehousing applications. Data loading can occur once or be a periodic process, but once the data is loaded, the app uses this graph to run traversals and perform calculations. Frequently the results are then stored back into a database or file for later consumption by other processes.
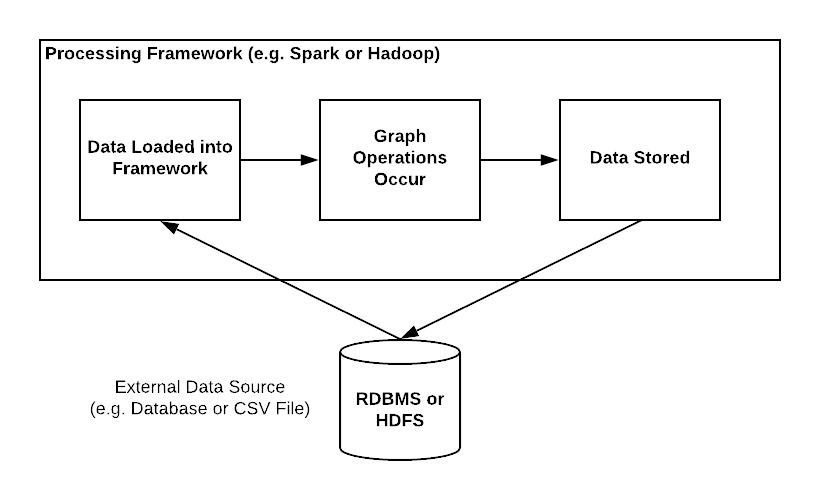
Graph frameworks focus on the ability to process global graph properties, such as identifying clusters, calculating centrality, or running unbounded graph queries like finding maximum tree depth. Due to the time and overhead required to calculate these global properties, graph frameworks are more often used to handle analytical (Online Analytical Processing or OLAP) workloads rather than transactional (Online Transaction Processing or OLTP) workloads. Graph frameworks accomplish these global analytical calculations using highly parallelized computational models optimized for parallel processing across many machines, many of which are based on the Pregel paper from Google. Three of the most popular graph processing frameworks on the market are discussed below:
Apache Giraph
Apache Giraph is one of the most popular graph frameworks (Facebook currently uses it) on the market and was built as an open source alternative to Pregel. Giraph is built on top of Apache Hadoop and uses a vertex-centric Bulk Synchronous Processing model to iteratively process graph queries across enormous datasets without a single point of failure.
Apache Spark GraphX
Apache Spark GraphX is an edge-centric graph processing framework built on top of Apache Spark. GraphX provides the ability to use a Pregel API within the framework of Spark to perform graph queries on data loaded into graphs, collections, maps, or other Resilient Distributed Datasets (RDD) upon which Spark is based.
GraphFrames
GraphFrames is a package for Apache Spark that is built on top of the newer DataFrames paradigm which was added to Spark to replace RDD’s. GraphFrames provides much the same capabilities as GraphX and should be the go-to option for those building graph applications on top of Spark. The update from using RDD’s with GraphX to using DataFrames in GraphFrames provides a significant uplift in computational performance and a simplification in code complexity.